Binning data in SQL
Generally when combining datasets you want to join them on some key. But sometimes you really want a range lookup like Excel’s VLOOKUP. A common example is binning values; you want to group values into custom ranges. While you could do this with a giant CASE statement, it’s much more flexible to specify in a separate table (for regular intervals you can do it with some integer division gymnastics). It is possible to implement VLOOKUP in SQL by using window functions to select the right rows.
For example to do a range lookup of users.amount on bins.bin to get bin.label you can use:
select u.*, label
from users as u
left join (
select bins.*, lead(bin) over (order by bin) as next_bin
from bins
) b on amount >= bin and (next_bin is null or amount < next_bin)The rest of this article elaborates on this example and some different ways to solve it.
Excel Approach
Suppose we have some users names and amounts.
| name | amount |
|---|---|
| dan | -1 |
| john | 1 |
| cat | 2 |
| sam | 3 |
| miguel | 4 |
| tom | 5 |
| kyle | 9 |
We want to bin this into custom bins (where the bin is unique and sorted):
| bin | label |
|---|---|
| 0 | 0-2 |
| 2 | 2-6 |
| 6 | 6-7 |
| 7 | 7+ |
This is simple in excel; if the latter range is labelled bin and the we can do VLOOKUP(C10, bins, 2) (where C10 is an example amount).
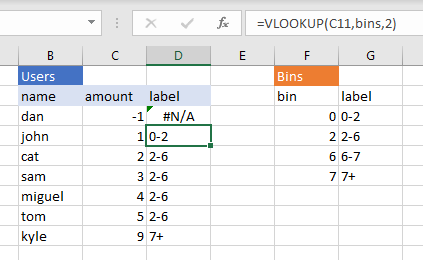
The result is:
| name | amount | label |
|---|---|---|
| dan | -1 | NULL |
| john | 1 | 0-2 |
| cat | 2 | 2-6 |
| sam | 3 | 2-6 |
| miguel | 4 | 2-6 |
| tom | 5 | 2-6 |
| kyle | 9 | 7+ |
Using double joins in SQL
The range lookup goes down the rows until it hits one that is larger than the value. We can do this by getting the maximum bin for which amount >= bin. We can then join this maximum bin back to the bin table to find out the label (fiddle)
select name, amount, label from (
select name, amount, max(bin) as max_bin
from users
left join bins on amount >= bin
group by name, amount
) as user_bin
left join bins on bin = max_bin
order by amountUnforutnately we need to group by all the key columns (here name and amount) and join to the bin table twice to do this. We can improve on this by using the row_number window function.
Using row_number
Another way to get the range lookup is to find the last row for which amount >= bin is true, using the row_number window function. In this case we just need partition keys that uniquely identify the row, in this example we can just use user (fiddle).
select name, amount, label from (
select name, amount, label,
row_number() over (partition by name order by bin desc) as rn
from users
left join bins on amount >= bin
) labelled_users
where coalesce(rn, 1) = 1Note that we use the coalesce to avoid dropping off the NULL labelled row.
The issue with this is we need to keep track of the key column, we can avoid that by directly implementing the range lookups on joining to the bins table.
Using a range join in SQL
Another way of looking at the range lookup is that we want the last row where amount >= bin, and so for the next row amount < bin. We can implement this using the lead window function (fiddle)
select u.*, label
from users as u
left join (
select bins.*, lead(bin) over (order by bin) as next_bin
from bins
) b on amount >= bin and (next_bin is null or amount < next_bin)This is the most flexible solution because we don’t need to know anything about the key columns of users. If you wanted a different kind of range lookup behaviour you could also implement it by changing lead to lag and moving around the inequalities. While we could have manually constructed next_bin in the table, using the lead function ensures that the bins are set right.
Creating a fallback for small values
In matching VLOOKUP we end up with anything before the first bin being labelled as NULL. We could try to create a minimum bin with the smallest allowable value (like the smallest integer, -Infinity for a float or the empty string), but this is messy. Another way to try to handle this is by adding a NULL to the bins for the initial fallback.
| bin | label |
|---|---|
| NULL | <0 |
| 0 | 0-2 |
| 2 | 2-6 |
| 6 | 6-7 |
| 7 | 7+ |
Then we can catch this case in our previous query, being careful to order NULL first (fiddle):
select u.*, label
from users as u
left join (
select bins.*, lead(bin) over (order by bin nulls first) as next_bin
from bins
) b on (bin is null or amount >= bin) and (next_bin is null or amount < next_bin)Finally giving
| name | amount | label |
|---|---|---|
| dan | -1 | <0 |
| john | 1 | 0-2 |
| cat | 2 | 2-6 |
| sam | 3 | 2-6 |
| miguel | 4 | 2-6 |
| tom | 5 | 2-6 |
| kyle | 9 | 7+ |
So we have a flexible SQL binning solution that relies on an external table. If we ever want to change the bins (or the labels) we can just update the bins table.