pyBART: Better Dependencies for Information Extraction
Dependency trees are a remarkably powerful tool for information extraction. Neural based taggers are very good and Universal Dependencies means the approach can be used for almost any language (although the rules are language specific). However syntax can get really strange requiring increasingly complex rules to extract information. The pyBART system solves this by rewriting the rules to be half a step closer to semantics than syntax.
I’ve seen that dependency based rules are useful for extracting skills from noun phrases and adpositions. But to get the long tail I tried to extract from conjugations and started writing some complex rules. An alternative would be to rewrite the dependency structure and then write simpler rules.
This is what pyBART does. Introduced by AllenAI in ACL2020 it comes with a paper, live demo and source code.
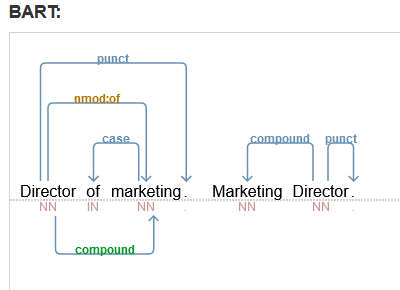
When I was trying to extract job titles I wrote an ad hoc rule to rewrite e.g. “Director of Marketing” to “Marketing Director” This type of “Genitive Construction” is given an extra “compound” dependency (in green below) so the phrase can be extracted the same way.
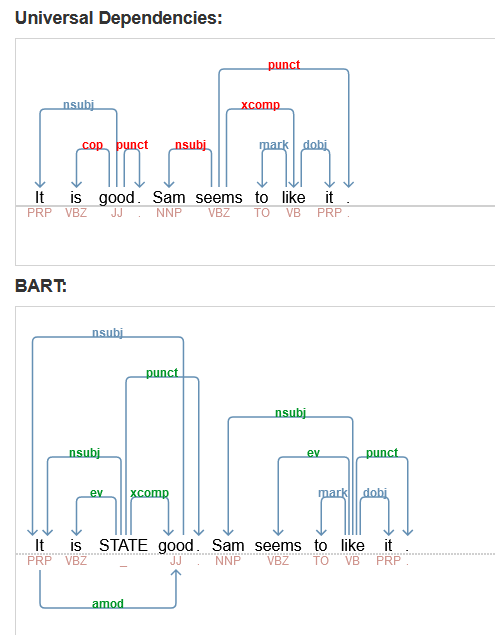
They try to make it easier to extract information by making the primary verb the root. For an indirect sentence like “Sam seems to like it” they move the root from “seems” to “like” and have “seems” as an event of “like”. To deal with copular sentences like “it is good” they add a phantom STATE node.
They also add “Uncertain” relations and “Alternate” relations to allow more recall in information extraction. This is really useful for common but not definite possibilities; and the rules could potentially learned with a machine learning model for specific corpora.
They’ve tried really hard to make it useful. It plugs into SpaCy, with Universal Dependendency Tagger, and so can be used with SpaCy’s dependency matcher.
For finding rules there is another useful AllenAI tool presented at ACL: Syntactic Search. There is a live demo where they show the new query language that is very easy to use and scalable. I tried to test my examples of searching for skills on Wikipedia, for example $experience :[t]in <>:[t]computing but the style of writing is so different on Wikipedia to job ads it’s not really useful. It’s not yet open source, as the code base is still a work in progress, so unless I send them a job corpora I can’t really test it out.
I sat in on the Q&A session for pyBART at ACL2020. Most of it was linguistics discussion over my head, but I really enjoyed how friendly and open everyone was. This is a “practical” implementation, taking a small step away from pure syntax towards semantics. While all the rules are grounded in solid linguistics, some of the ideas like an “event” don’t exist for philosophical reasons in Universal Dependencies. This approach could be extended to other languages, but the rules (and some verb lists) would need to be appropriately changed to match that language.
There was also some interesting discussion about using higher trees rather than the “flat” projection of dependency triples for information extraction. I would have no idea how to do this though!
The rewriting rules are written in an ad hoc manner. It was suggested that a graph rewriting tool like OGRE (from a Phd Thesis) would allow the rules to be written by linguists, be more maintainable and less likely to interfere in weird ways.
Finally there was some discussion of how it related to UDep Lambda (source code). The conclusion was UDep Lambda is much more theoretical, and harder for people to use in practice. But it sounds like an interesting (crazy?) idea to look more into later.