Type of details (comment, comment_ranking, poll, story, job, pollopt)
id
INTEGER
The item’s unique id.
parent
INTEGER
Parent comment ID
descendants
INTEGER
Number of story or poll descendants
ranking
INTEGER
Comment ranking
deleted
BOOLEAN
Is deleted?
df.dtypes
title string
url string
text string
dead boolean
by string
score Int64
time Int64
timestamp datetime64[ns, UTC]
type string
parent Int64
descendants Int64
ranking Int64
deleted boolean
dtype: object
Here’s a sample of the dataframe.
Note that we can view any individual item by appending the id in the URL https://news.ycombinator.com/item?id=
df
title
url
text
dead
by
score
time
timestamp
type
parent
descendants
ranking
deleted
id
27405131
<NA>
<NA>
They didn't say they <i>weren't</i> …
<NA>
chrisseaton
<NA>
1622901869
2021-06-05 14:04:29+00:00
comment
27405089
<NA>
<NA>
<NA>
27814313
<NA>
<NA>
Check out <a href=“https://www.remno…
<NA>
noyesno
<NA>
1626119705
2021-07-12 19:55:05+00:00
comment
27812726
<NA>
<NA>
<NA>
28626089
<NA>
<NA>
Like a million-dollars pixel but with letters….
<NA>
alainchabat
<NA>
1632381114
2021-09-23 07:11:54+00:00
comment
28626017
<NA>
<NA>
<NA>
27143346
<NA>
<NA>
Not the question…
<NA>
SigmundA
<NA>
1620920426
2021-05-13 15:40:26+00:00
comment
27143231
<NA>
<NA>
<NA>
29053108
<NA>
<NA>
There’s the Unorganized Militia of the United …
<NA>
User23
<NA>
1635636573
2021-10-30 23:29:33+00:00
comment
29052087
<NA>
<NA>
<NA>
…
…
…
…
…
…
…
…
…
…
…
…
…
…
27367848
<NA>
<NA>
Housing supply isn’t something that can’t chan…
<NA>
JCM9
<NA>
1622636746
2021-06-02 12:25:46+00:00
comment
27367172
<NA>
<NA>
<NA>
28052800
<NA>
<NA>
Final Fantasy XIV has been experiencing consta…
<NA>
amyjess
<NA>
1628017217
2021-08-03 19:00:17+00:00
comment
28050798
<NA>
<NA>
<NA>
28052805
<NA>
<NA>
How did you resolve it?
<NA>
8ytecoder
<NA>
1628017238
2021-08-03 19:00:38+00:00
comment
28049375
<NA>
<NA>
<NA>
26704924
<NA>
<NA>
This hasn't been my experience being vega…
<NA>
pacomerh
<NA>
1617657938
2021-04-05 21:25:38+00:00
comment
26704794
<NA>
<NA>
<NA>
27076885
<NA>
<NA>
Death services tread a very fine moral line. …
<NA>
curryst
<NA>
1620400897
2021-05-07 15:21:37+00:00
comment
27075961
<NA>
<NA>
<NA>
4155063 rows × 13 columns
Every post has a time, timestamp and parent.
No post has a ranking.
df.notna().mean().apply('{:0.2%}'.format)
title 8.97%
url 8.46%
text 88.57%
dead 3.87%
by 97.22%
score 9.04%
time 100.00%
timestamp 100.00%
type 100.00%
parent 90.64%
descendants 7.00%
ranking 0.00%
deleted 2.78%
dtype: object
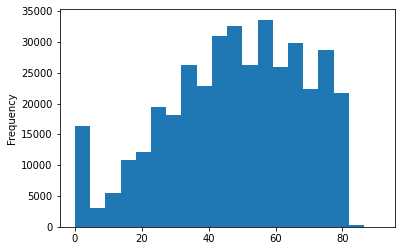
We filtered to data in 2021, so it’s all in this range
Based on the 4am rule is looks like the most common timezone is around UTC-1.
This is slightly surprising, I would expect it could be closer to a US timezone (around -4 to -8). Maybe there’s more posting from other regions than I’d have thought.
A story consists of a title, and it looks like either a url or text
story = df.query('type=="story"')story
title
url
text
dead
by
score
time
timestamp
type
parent
descendants
ranking
deleted
id
28540306
CoinCircle for Life
<NA>
Hello, Lets join us to CoinCircle for our bett…
True
rend-airdrop
1
1631719412
2021-09-15 15:23:32+00:00
story
<NA>
<NA>
<NA>
<NA>
26273978
Find the number of third-party privacy tracker…
<NA>
Exodus Privacy is a non-profit organization th…
True
moulidorai
1
1614341393
2021-02-26 12:09:53+00:00
story
<NA>
<NA>
<NA>
<NA>
27214431
Ask HN: Desk Recommendations?
<NA>
I often see standing desk recommendations here…
True
throwaw9l938ni
1
1621458219
2021-05-19 21:03:39+00:00
story
<NA>
<NA>
<NA>
<NA>
25705820
Demand Hunter Biden Be Arrested
<NA>
There are so many pictures of Hunter Biden, Jo…
True
bidenpedo
1
1610232470
2021-01-09 22:47:50+00:00
story
<NA>
<NA>
<NA>
<NA>
26110009
Deep learning multivariate nonlinear regression
<NA>
Does deep learning really work for regression …
True
dl_regression
1
1613095333
2021-02-12 02:02:13+00:00
story
<NA>
<NA>
<NA>
<NA>
…
…
…
…
…
…
…
…
…
…
…
…
…
…
28773509
Apple to face EU antitrust charge over NFC chip
https://www.reuters.com/technology/exclusive-e…
<NA>
<NA>
nojito
170
1633530062
2021-10-06 14:21:02+00:00
story
<NA>
219
<NA>
<NA>
26400239
The Roblox Microverse
https://stratechery.com/2021/the-roblox-microv…
<NA>
<NA>
Kinrany
173
1615306495
2021-03-09 16:14:55+00:00
story
<NA>
203
<NA>
<NA>
27559832
Safari 15 on Mac OS, a user interface mess
https://morrick.me/archives/9368
<NA>
<NA>
freediver
463
1624104913
2021-06-19 12:15:13+00:00
story
<NA>
353
<NA>
<NA>
26992205
Stock Market Returns Are Anything but Average
https://awealthofcommonsense.com/2021/04/stock…
<NA>
<NA>
RickJWagner
222
1619783307
2021-04-30 11:48:27+00:00
story
<NA>
413
<NA>
<NA>
29738298
Tokyo police lose 2 floppy disks containing in…
https://mainichi.jp/english/articles/20211227/…
<NA>
<NA>
ardel95
232
1640883038
2021-12-30 16:50:38+00:00
story
<NA>
218
<NA>
<NA>
387194 rows × 13 columns
Stories normally have title and a URL, and occasionally have text.
They’re almost always by someone, and have a score. They never have a parent (they’re always top level), but they normally have descendants.
Some are dead (removed by Hacker News) and some are deleted (removed by the author).
( story .notna() .mean() .apply('{:0.1%}'.format))
title 95.9%
url 90.5%
text 4.9%
dead 22.5%
by 96.6%
score 96.6%
time 100.0%
timestamp 100.0%
type 100.0%
parent 0.0%
descendants 75.1%
ranking 0.0%
deleted 3.4%
dtype: object
By seems to be missing only for deleted stories
( story .query('by.isna()'))
title
url
text
dead
by
score
time
timestamp
type
parent
descendants
ranking
deleted
id
26779931
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1618238390
2021-04-12 14:39:50+00:00
story
<NA>
<NA>
<NA>
True
26122158
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1613203434
2021-02-13 08:03:54+00:00
story
<NA>
<NA>
<NA>
True
25699401
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1610190538
2021-01-09 11:08:58+00:00
story
<NA>
<NA>
<NA>
True
26206857
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1613848074
2021-02-20 19:07:54+00:00
story
<NA>
<NA>
<NA>
True
26316571
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1614700390
2021-03-02 15:53:10+00:00
story
<NA>
<NA>
<NA>
True
…
…
…
…
…
…
…
…
…
…
…
…
…
…
28201589
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1629140598
2021-08-16 19:03:18+00:00
story
<NA>
<NA>
<NA>
True
26786548
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1618271177
2021-04-12 23:46:17+00:00
story
<NA>
<NA>
<NA>
True
26689984
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1617548611
2021-04-04 15:03:31+00:00
story
<NA>
<NA>
<NA>
True
27349809
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1622509992
2021-06-01 01:13:12+00:00
story
<NA>
<NA>
<NA>
True
25913791
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
1611651379
2021-01-26 08:56:19+00:00
story
<NA>
<NA>
<NA>
True
13300 rows × 13 columns
Every story has a by unless it’s deleted or dead.
( story .query('by.isna() & deleted.isna() & dead.isna()'))
title
url
text
dead
by
score
time
timestamp
type
parent
descendants
ranking
deleted
id
How do I make a link in a text submission?
You can’t. This is to prevent people from submitting a link with their comments in a privileged position at the top of the page. If you want to submit a link with comments, just submit it, then add a regular comment.
title 0.0%
url 0.0%
text 97.2%
dead 2.0%
by 97.3%
score 0.0%
time 100.0%
timestamp 100.0%
type 100.0%
parent 100.0%
descendants 0.0%
ranking 0.0%
deleted 2.7%
dtype: object
Parents
We can look at the type of the parent’s comments (they’ll sometimes be missing if the parent was posted before our cutoff date.
Most comments parent is another comment in a thread.
CPU times: user 2.4 s, sys: 28.1 ms, total: 2.43 s
Wall time: 2.43 s
id
27405131 27405024
27814313 27807850
28626089 28625485
27143346 27142955
29053108 29052012
...
27367848 <NA>
28052800 28049873
28052805 28046997
26704924 26704392
27076885 27074332
Name: parent, Length: 4155063, dtype: object
We can do this iteratively to find all the parents.
When there is no parent we’ll return <NA>; this particular way of doing it gets faster the fewer non-null elements there are.
from tqdm.notebook import tqdmMAX_DEPTH =50df['parent0'] = df['parent']for idx in tqdm(range(MAX_DEPTH)): last_col =f'parent{idx}' col =f'parent{idx+1}' df[col] = df[last_col].map(parent_dict, na_action='ignore')if df[col].isna().all():del df[col]break
0%| | 0/50 [00:00<?, ?it/s]
We can now see all the parents of any element
df.filter(regex='parent\d+')
parent0
parent1
parent2
parent3
parent4
parent5
parent6
parent7
parent8
parent9
parent10
parent11
parent12
parent13
parent14
parent15
parent16
parent17
parent18
parent19
parent20
parent21
parent22
parent23
parent24
parent25
parent26
parent27
parent28
parent29
parent30
parent31
parent32
parent33
parent34
parent35
parent36
parent37
parent38
parent39
parent40
parent41
parent42
parent43
id
27405131
27405089
27405024
27404902
27404548
27404512
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
27814313
27812726
27807850
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
28626089
28626017
28625485
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
27143346
27143231
27142955
27142884
27142567
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
29053108
29052087
29052012
29051947
29051758
29051607
29051478
29051448
29051365
29051109
29043296
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
27367848
27367172
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
28052800
28050798
28049873
28049688
28049620
28049359
28048919
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
28052805
28049375
28046997
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
26704924
26704794
26704392
26703874
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
27076885
27075961
27074332
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
<NA>
4155063 rows × 44 columns
One useful concept is the root, the parent that has no parents itself (generally because it’s top level, but sometimes because the parent isn’t in the dataframe).
%%timeroot =Nonefor col in df.filter(regex='parent\d+').iloc[:,::-1]:if root isNone: root = df[col]else: root = root.combine_first(df[col])df['root'] = root
CPU times: user 11.1 s, sys: 826 ms, total: 11.9 s
Wall time: 11.9 s
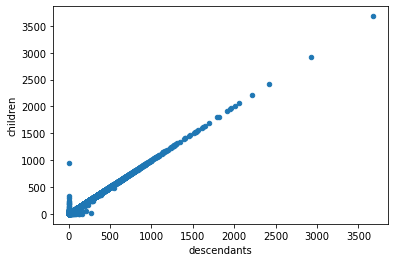
We can also get the depth; how parents does it have?
All the cases that error on this side there are no descendants
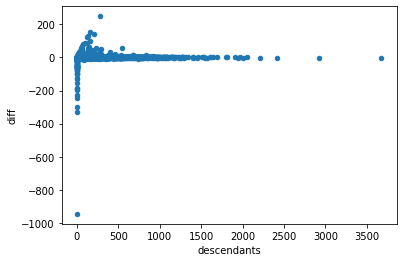
children_counts[children_counts['diff'] <-100]
descendants
children
diff
28733467
0
197.0
-197.0
28761974
0
247.0
-247.0
28752512
0
297.0
-297.0
25669864
0
946.0
-946.0
25594068
0
329.0
-329.0
25598606
0
230.0
-230.0
25598768
0
191.0
-191.0
25597891
0
184.0
-184.0
25591202
0
153.0
-153.0
25590022
0
129.0
-129.0
25732809
0
127.0
-127.0
There are a few cases where it’s not in the index at all (maybe the story was posted just before the cutoff? we could confirm this with the children dates)
HackerNews has it’s own formatting specification called formatdoc
Blank lines separate paragraphs.
Text surrounded by asterisks is italicized. To get a literal asterisk, use * or **.
Text after a blank line that is indented by two or more spaces is reproduced verbatim. (This is intended for code.)
Urls become links, except in the text field of a submission.
If your url gets linked incorrectly, put it in and it should work.
The concepts are:
italics
paragraphs
code
links
In our dataset it’s been rendered as HTML
pd.options.display.max_colwidth =400
comments[['text']].head()
text
id
27405131
They didn't say they <i>weren't</i> afraid of loss at the top, but that they <i>were also</i> afraid of loss at the bottom.
27814313
Check out <a href=“https://www.remnote.io/” rel=“nofollow”>https://www.remnote.io/</a>
28626089
Like a million-dollars pixel but with letters.<p><a href=“https://project-memento.com” rel=“nofollow”>https://project-memento.com</a>
27143346
Not the question…
29053108
There’s the Unorganized Militia of the United States and if you’re a male US citizen odds are good that you’re a statutory[1] member. It’s completely distinct from Selective Service.<p>[1] <a href=“https://www.law.cornell.edu/uscode/text/10/246” rel=“nofollow”>https://www.law.cornell.edu/uscode/text/10/246</a>
stories[['text']].dropna().tail()
text
id
25904433
And what's your reading frequency for books?
25940949
Hello - I have received a contract for promotion but it has new clauses, some of which are a little over the top. Is there some community that offers help with this? I'm aware a lawyer is a good idea, but besides that?
27912487
Thinking of moving to Berlin for access to a market with better opportunities for software developers.<p>Background is 5+ years experience in enterprise development roles, docker/K8S/cloud experience included. EU citizen so visa not a problem, also speak German.<p>What are salaries like at the moment and is it still a good option for developers?
26902219
I have doubts about my intelligence. I'm trying to get a Data Science internship and had several interviews. All of them were on combinatorics/algorithms, and I failed them, though they were relatively simple. I’ve always been bad at this kind of stuff: I have trouble focusing, especially paying attention to details. I also forget things all the time<p>I’m a 3rd-year student at a uni…
27698322
Heya! Not the usual sort of thing to be posted here, but I wanted to show off what I made yesterday. Here's a sample page about H1-B visas issued in Bogota:<p><https://visawhen.com/consulates/bogota/h1b><p>The code is source-available (not open source) at <https://github.com/underyx/visawhen>. It's my first time choosing a sour…
We can remove all the HTML encoded entities (like ') using html.unescape.
They didn’t say they <i>weren’t</i> afraid of loss at the top, but that they <i>were also</i> afraid of loss at the bottom.
27814313
Check out <a href=“https://www.remnote.io/” rel=“nofollow”>https://www.remnote.io/</a>
28626089
Like a million-dollars pixel but with letters.<p><a href=“https://project-memento.com” rel=“nofollow”>https://project-memento.com</a>
27143346
Not the question…
29053108
There’s the Unorganized Militia of the United States and if you’re a male US citizen odds are good that you’re a statutory[1] member. It’s completely distinct from Selective Service.<p>[1] <a href=“https://www.law.cornell.edu/uscode/text/10/246” rel=“nofollow”>https://www.law.cornell.edu/uscode/text/10/246</a>
Counting the tags:
Most items don’t have any tags at all
Paragraphs are the most common, and they are never closed
Links are second most common, and are always closed
Italics are third, and are always closed
Pre and code are less common, and occur with the same frequency. They are always closed.
I’m also surprised how common links are and multiparagraph comments are.
The programmers, like the poets, work only slightly removed from pure thought-stuff. They build their castles in the air, from air, creating by exertion of the imagination. Few media of creation are so flexible, so easy to polish and rework, so readily capable of realizing grand conceptual structures.<p><pre><code> - Fred Brooks, The Mythical Man Month</code></pre>
28624403
<p><pre><code> > They’re grown adults capable of making their own decisions and their own mistakes.</code></pre>a society, “ones own mistakes” can have effects on those around you (e.g mask wearing, vaccine (not)taking, spreading misinformation etc) which can result in unintentional hospitalization or death of others<p>we dont live in isolated bubbles, so there is a limit to how far we…
25657174
A few cool tricks I use with window functions:<p>1- To find blocks of contiguous values, you can use something similar to Gauss’ trick for calculating arithmetic progressions: sort them by descending order and add each value to the row number. All contiguous values will add to the same number. You can then apply max/min and get rows that correspond to the blocks of values.<p><pre><code> sel…
27856678
Ah… the “Dark Forest Theory”. People really put way too much unnecessary time on it.<p>If the theory was true, then the first thing those “tree-body man” would reasonably do is to just destroy the solar system straight away with that super illegal (to the law of physics) raindrop probe. A civilization with the intention of discover and kill will definitely make their probes efficient kill de…
27027255
I’m sure you can design schemas screwy enough that Rust can not even express them[0] but that one seems straightforward enough:<p><pre><code> #[derive(Serialize, Deserialize)]#[serde(tag = “kind”, rename_all = “lowercase”)]enum X {Foo { foobar: String },Bar {#[serde(skip_serializing_if = “Option::is_none”)]foobar: Option<f64>, …
…
…
29180796
Good job, it’s racist !<p>I wrote this:<p>Typed:<p><pre><code> Q : Qui sont les ennemis de la France ?R :</code></pre>:<p><pre><code> Q : Qui sont les ennemis de la France ?R : Les ennemis de la France sont les ennemis de l’humanité.Q : Quelle est la différence entre un musulman et un terroriste?R : Un musulman est un terroriste …
26078503
Partial functions are not the same thing as “partially applied functions”. Partial functions means that not every element of the domain is mapped to an element of the range, for example:<p><pre><code> divTenBy :: Double -> DoubledivTenBy n = 10 / n</code></pre>you actually call the above function you get a runtime exception. We really don’t like functions that do this; they are…
26946115
> Easily center anything, horizontally and vertically, with 3 lines of CSS<p>This can actually be done with 2 lines now!<p><pre><code> .center {display: grid;place-items: center;}</code></pre>
25676392
Early career Comp./SW Engineer looking for meaningful and beneficial work alongside interesting people.academic and research experience in high performance computing, wireless sensing, machine learning, biomedical engineering, astronautics.<p>Some interests include: Biomedical engineering, environmentalism, space exploration & development, scientific computing, ML/AI –<p>Generally…
27478974
I’m building a language (<a href=“https://tablam.org” rel=“nofollow”>https://tablam.org</a>) that, hopefully, could become the base for excel/access alternative.<p>lisp is <i>not</i> the better fir for excel, to see why, check this:<p><pre><code> “The memory models that underlie programming languages”</code></pre><a href=“http://canonical.org/~kragen/memory-models/” rel=“nofollow”>http://…
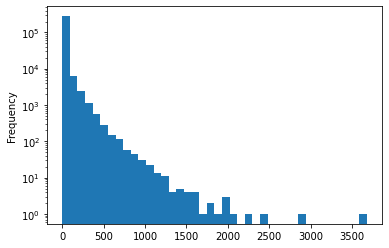
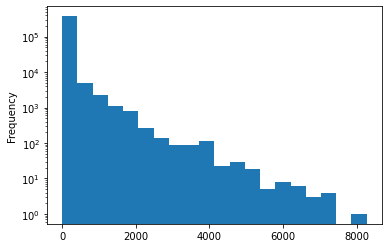
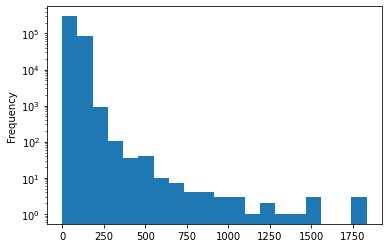
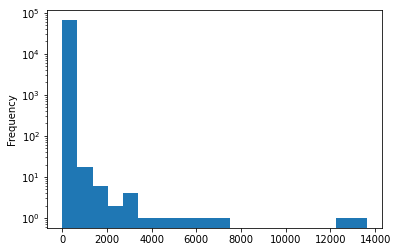
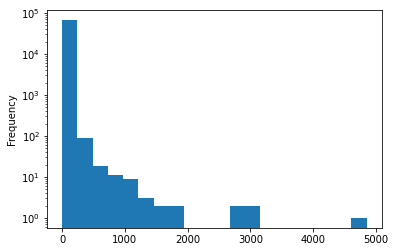
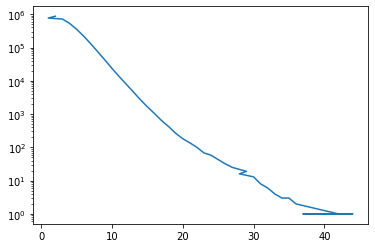
Comments
3766009 rows × 13 columns
Comments can’t have a tile or a URL.
They almost always have a
textand aby(I’d guess it’s missing for deleted and dead threads).We don’t ever get a
scoreorrankingordescendantseven though these things may make sense.