Bootstrapping a book classifier
I’m working on a project to extract books from Hacker News. Most HackerNews posts aren’t about books, and it would be extremely tedious to manually annotate examples when most of them are negative. Instead I used different heuristics to determine whether a book contains a title, that can then be used for weak labelling.
My main takeaway is that zero shot classification seems like a great starting point for building a classifier. It doesn’t do as well as domain specific rules but it does well enough to be useful and has large coverage.
Methods
The methods I tried are:
- Using a list of “Seed Books” as a gazetteer. This is a general approach in NER but the difficulty is selecting the items.
- Finding comments in Hacker News Threads asking for book recommendations.
- Using the Work of Art entity using the SpaCy transformer model.
- Using an NLI based Zero Shot Classification with the prompt “This comment mentions a book by title.” (with a cutoff of 80% probability).
- Direct child comments of the “Seed Books” comments
- Direct parent comments of the “Seed Books” comments
- Siblings of the “Seed Books” comments (excluding “Seed Books” comments themselves)
Results
For each of the heuristics I calculated the positive label rate and estimated the precision. The positive label rate is the number of examples labelled as positive; this tells us something about the number of labels. To estimate precision I annotated 20 random examples and calculated the number of comments that contain a book title.
| Heuristic | Positive Label Rate | Precision | General? | Inference Speed |
|---|---|---|---|---|
| Seed Book (Gazetteer) | 0.06% | 18/20 | Sort of | Medium |
| Ask HN Book Comment | 0.04% | 11/20 | No | Fast |
| Work of Art | 2.9% | 7/20 | A little | Slow |
| Zero Shot Classifier | 2.6% | 6/20 | Yes | Slow |
| Child of Seed Book | 0.06% | 6/20 | No | Fast |
| Parent of Seed Book | 0.05% | 5/20 | No | Fast |
| Sibling of Seed Book | 0.7% | 2/20 | No | Fast |
The zero shot classifier comes out as a good comprimise of being a general approach that gets reasonable precision with very high coverage. The gazetteer has the highest precision, but has low coverage and is likely to have very low diversity of examples, and requires a lot of effort to maintain; nearby comments may contain more examples but they all have a lower precision than the other methods. The Ask HN Book Comment threads have a good precision and high diversity but are a very small sample - this could be good for a weak labeller. The Work of Art approach is comparable to the zero shot classifier (in precision because we’re having to exclude titles of movies, books, and songs), but requires the specific labelled data.
Overlap
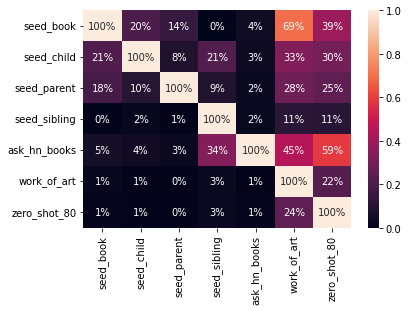
One advantage of combining these different heuristics is getting a diversity of examples. To understand how they are related I calculated the confidence for each pair of rules:
\[\mathrm{conf}(X \Rightarrow Y) = P(Y | X) = \frac{\mathrm{supp}(X \cap Y)}{ \mathrm{supp}(X) }\]
Most of the density is on the columns for work_of_art and zero_shot_80 because they have the most coverage. These two have only about 25% overlap, and about 35% precision, meaning that combining them will give more diverse examples. Looking at their overlap with seed_books which has very high precision indicates there are some obvious examples both of them miss (the seed books all used title case which is likely why work_of_art worked so well).
See the related notebook for the details.
Next steps
Now that we have all these weak labelling functions and an idea how they work, they can help pick out examples that are likely to have a book title. The goal is to have a model that can actually find the book titles, so a good approach would be to take samples from each of these heuristics (perhaps in proportion to its precision) and manually label NER entities. Another option would be to fine tune the work_of_art label in an NER model, since it predicts the actual entity span. Or we could use question answering as zero shot NER to predict spans and correct them.