Tips for Extracting Data with Beautiful Soup
Beautiful soup can be a useful library for extracting information from HTML. Unfortunately there’s a lot of little issues I hit working with it to extract data from a careers webpage using Common Crawl. The library is still useful enough to work with; but the issues make me want to look at alternatives like lxml (via html5-parser).
The source data can be obtained at the end of the article.
Use a good HTML parser
Python has an inbuilt html.parser, but it often misparses HTML. You’re better off using html5lib (or maybe html5-parser).
For example with this document I tried to extract the description with html.parser.
import bs4
soup = bs4.BeautifulSoup(html, 'html.parser')
description = soup.select_one('.txt-pre-line')However it gave me back an empty span.
<div class="txt-pre-line">
<ul></ul></div>But viewing it in the browser shows the text should be there.
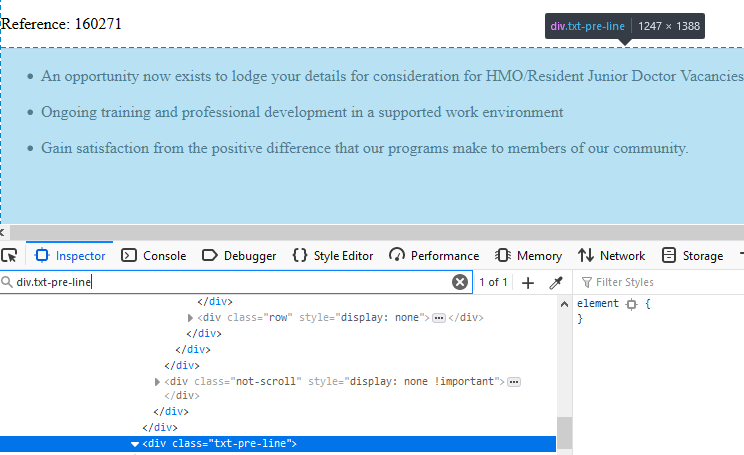
This was fixed by switching the “features” to html5lib.
soup = bs4.BeautifulSoup(html, 'html5lib')
description = soup.select_one('.txt-pre-line')This gave the full HTML; here’s a small snipped
<div class="txt-pre-line">
<ul><br/>
<li>An opportunity now exists to lodge your details for consideration for ...
<p>We Barwon Health is proud to be Totally Smoke Free.</p>
</div>Extracting Structured data with selectors
The webpage contained a lot of examples of key value pairs marked up like this:
<p class="txt-info location txt-one-line"><span class="txt-bold">Location: </span>Geelong</p>The pairs all occurred with a class of txt-info so could be extracted using the CSS selector soup.select('.txt-info') returning a list of these. The key is always in a txt-bold class and so can be retrieved with .select_one('.txt-bold'). To get everything the value to the right of the key we can use .next_siblings which generates the sequence ['Geelong'].
Converting to text
The .next_siblings will generate a mixture of Beautiful Soup objects: Tag, NavigableString and Comment.
To turn a Tag into text you can use the .get_text() method which extracts all the text. Unfortunately it also includes whitespace padding, so in this example you would get all the whitespace.
<p class="txt-info txt-one-line">
<span class="refnum">
<span class="txt-bold">Reference: </span>
<span>160271</span>
</span>
</p>You can remove the excess whitespace by invoking .get_text(strip=True).
However it doesn’t interpret tags in the text; for example a <p> or a <br/> should be turned into a line break, but they’re not. You can pass a separator argument which will join the tags, but setting this to \n puts a newline between all tags, including <b> and <a> where it shouldn’t be. For good HTML to text conversion we’d need to look somewhere else.
To turn a NavigableString into text we can just wrap it in str. To convert all the siblings we can need to treat them separately like:
''.join(
str(
sib.get_text() if isinstance(sib, bs4.element.Tag) else sib
).strip()
for sib in key.next_siblings)Serializing
Trying to pickle a Beautiful Soup object leads to an error like this:
Traceback (most recent call last):
File "./02_merge_data.py", line 50, in <module>
pickle.dump(data, f)
File "/home/eross/.virtualenvs/ds/lib/python3.6/site-packages/bs4/element.py", line 731, in __getnewargs__
return (str(self),)
RecursionError: maximum recursion depth exceeded while getting the str of an objectThis is because everything is connected to everything else, which is what lets you navigate the soup. To save the HTML I just wrap a Tag in str.
str(soup.select_one('.txt-pre-line'))Getting the data
If you want to rerun any of this script you can download the data from Common Crawl like this:
curl -H "Range: bytes=403742602-403762161" https://data.commoncrawl.org/crawl-data/CC-MAIN-2020-16/segments/1585371656216.67/warc/CC-MAIN-20200406164846-20200406195346-00353.warc.gz |\
gzip -dc |\
tail -n +35 >\
data.html